
Zusammenfassung
Du willst wissen, wie gut deine Website technisch aufgestellt ist? Dann lohnt sich ein Blick auf Screaming Frog – eines der mächtigsten Tools zur SEO-Analyse. In diesem Beitrag zeige ich dir, was der Website-Crawler kann, für wen er sich lohnt und wie du das Maximum aus dem Tool herausholst – ganz ohne Programmierkenntnisse.
Aktualisiert am 6. August 2025
Was kann Screaming Frog? Es erfasst jede URL und zeigt dir vorhandene Informationen wie Alt-Tags oder Meta-Descriptions und auch technische Fehler deiner Website.
Screaming Frog ist ein Tool zur Website-Analyse, das Webseiten crawlt und die gewonnenen Daten übersichtlich in verschiedenen Registerkarten darstellt. Die Software wird auf Windows oder Mac installiert und ermöglicht das tägliche Untersuchen beliebig vieler Websites. In der kostenlosen Version ist der Crawl jedoch auf 500 URLs pro Website begrenzt – inklusive Bilder, Skripte und andere Dateien. Für viele Anwendungsfälle reichen diese 500 URLs aus, um bereits wertvolle Einblicke in die Website-Struktur und mögliche SEO-Probleme zu erhalten.
Was bedeutet Crawling?
To crawl bedeutet krabbeln oder kriechen und meint in unserem Fall die Webcrawler – z.B. von Google – die das World Wide Web durchsuchen, Daten analysieren, speichern und strukturieren. Diese Crawler sind verschiedene kleine Software-Programme und heißen Spider, Bot, Crawler etc., sie haben verschiedene Funktionen: die Freshbots schauen u.a. mal kurz, ob die Seite aktuell ist, die Deepbots untersuchen die jeweilige Seite einer Homepage genauer.
Diese Spider klettern von Link zu Link und sammeln Informationen.
Ich habe dir eine kurze Bedienungsanleitung zusammengestellt, nicht alle möglichen Optionen stelle ich in allen Einzelheiten vor, aber das Wichtigste in Wort und Bild 🙂
Was macht Screaming Frog?
Analysieren von Seitentiteln und Metadaten
Aus Seitentitel und Meta-Description wird in der Regel das Serp-Snippet gebildet, also das Schnipsel auf der Google-Ergebnisseite, das deine Homepage anmoderiert.
Wie sind deine Seitentitel und Meta-Beschreibungen: zu lang, zu kurz, doppelt oder fehlend?
Wie lang darf mein SERP Snippet sein?
Meta-Description gut: zwischen 70 und 160 Zeichen einschl. Leeranschläge.
Titel: 580 Pixel (Desktop) beziehungsweise 920 Pixel (Mobile)
Description: 990 Pixel (Desktop) beziehungsweise 1.300 Pixel (Mobile)
Teste dein Snippet: sistrix.com/de/serp-snippet-generator ↑
Defekte Links und Umleitungen finden
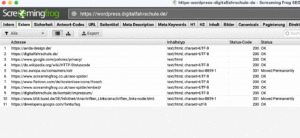
Über die Status Codes erfährst du, ob alles rund läuft. Defekte Links laufen z.B. als 404.
Diese Informationen sagen dir entweder selber etwas, wenn nicht, einfach exportieren und diese Datei an deine Webdesigner/ Programmierer senden. Für uns sind folgende Statuscodes interessant:
- 200 → OK → Die Anfrage wurde erfolgreich bearbeitet und das Ergebnis der Anfrage wird in der Antwort übertragen.
- 301 → Moved Permanently → Die angeforderte Ressource steht ab sofort unter der im „Location“-Header-Feld angegebenen Adresse bereit (auch Redirect genannt). Die alte Adresse ist nicht länger gültig.
- 302 → Found (but Moved Temporarily) → Die angeforderte Ressource steht vorübergehend unter der angegebenen Adresse bereit. 302-Weiterleitungen sind aus SEO-Sicht in die Kritik geraten, da sie in der Vergangenheit von Suchmaschinen missverstanden wurden, was zu Ranking-Verlusten führen konnte – und weil sie missbraucht werden konnten (z. B. durch URL-Hijacking).
- 404 → Not Found → Die angeforderte URL wurde nicht gefunden. Dieser Statuscode kann ebenfalls verwendet werden, um eine Anfrage ohne näheren Grund abzuweisen. Links, die auf solche Fehlerseiten verweisen, werden auch als Tote Links bezeichnet.
Eine Übersicht (und weitere Erklärung der technischen Begriffe) aller Statuscodes bei Wikipedia ↑
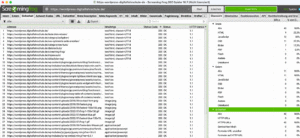
Überblick über die genutzten Bilder
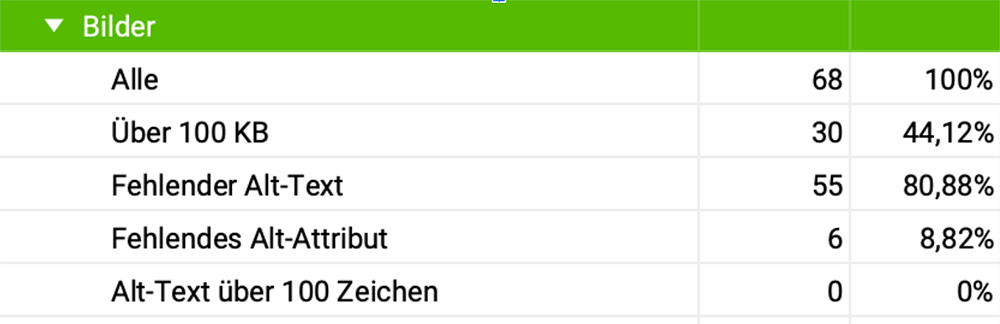
Welche Dateiformate für Bilder wurden genutzt, welche Dateinamen vergeben, nutzen alle Bilder und Grafiken einen Alt-Tag? Wenn du dir unsicher bist, was das bedeutet, lese meinen Artikel: SEO Bilder – Alt-Tag & Title-Tag – verstehen, anwenden →
Diese Informationen gibt dir Screaming Frog:
- Anzahl der verwendeten Bilder auf der Website
- Über 100 KB
- Fehlender Alt-Text
- Fehlende Alt-Attribute
- Alt-Text zu lang – also über 100 Zeichen
Wenn du auf eines der Elemente klickst öffnet sich eine Liste mit den analysierten Bild-Dateien

Doppelte Inhalte (Duplicate Content)
Finde exakte doppelte URLs, teilweise doppelte Elemente wie Seitentitel, Beschreibungen oder Überschriften und finde Seiten mit geringem Inhalt.
Überprüfung von Robots & Direktiven
Zeige URLs an, die durch robots.txt, Meta-Robots oder X-Robots-Tag-Direktiven wie “noindex” oder “nofollow” blockiert sind, sowie Kanonische URLs (mit denen doppelter Content vermieden werden kann)
Website-Architektur visualisieren
Bewerte interne Verlinkung und die URL-Struktur mithilfe von interaktiven Crawl- und verzeichnisgesteuerten Diagrammen und Baumdiagramm-Visualisierungen.
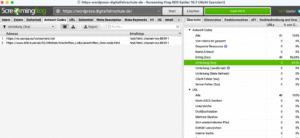
Registerkarten ein- oder ausblenden
Du kannst die Registerkarten ausblenden, die du nicht nutzt. Weil wir sowieso bei der kostenfreien Variante von Screaming Frog sind, reichen die Registerkarten, die wir hier besprechen. Ausblenden geht wie folgt:
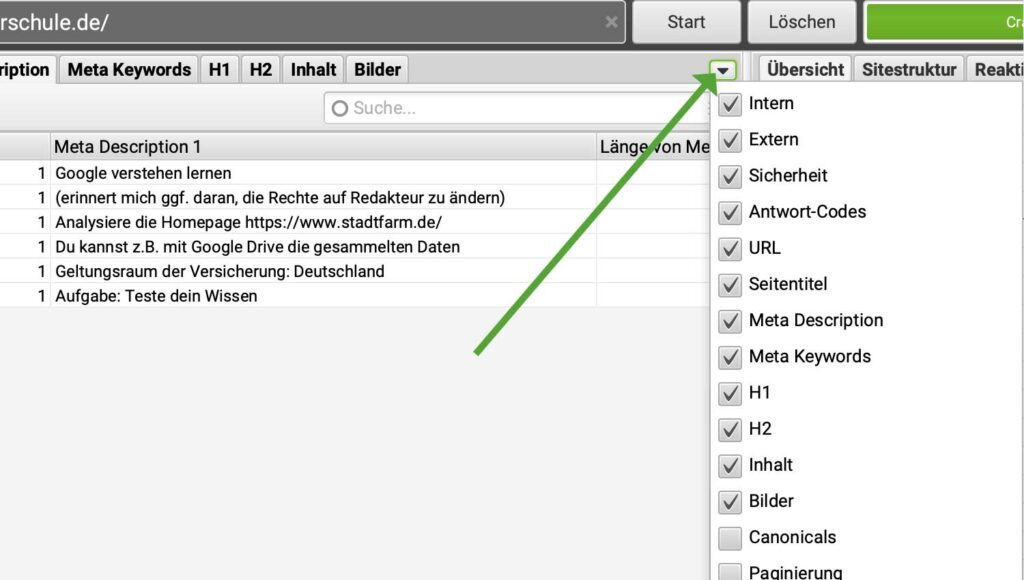
Registerkarten von Screaming Frog in Bildern

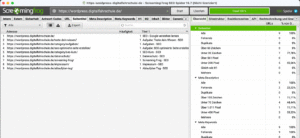
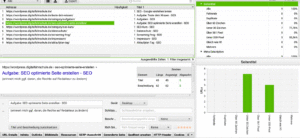
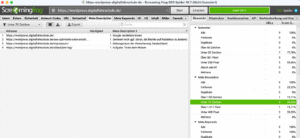




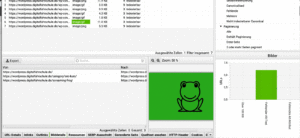
Registerkarten in der Fußzeile
In der Fußzeile bekommst du viele weitere Informationen über das ausgewählte Element. Nicht immer funktioniert alles, d.h. ich empfehle dir: blende die von dir nicht genutzten Funktionen einfach aus! Weiter unten eine Erklärung, was was bedeutet.
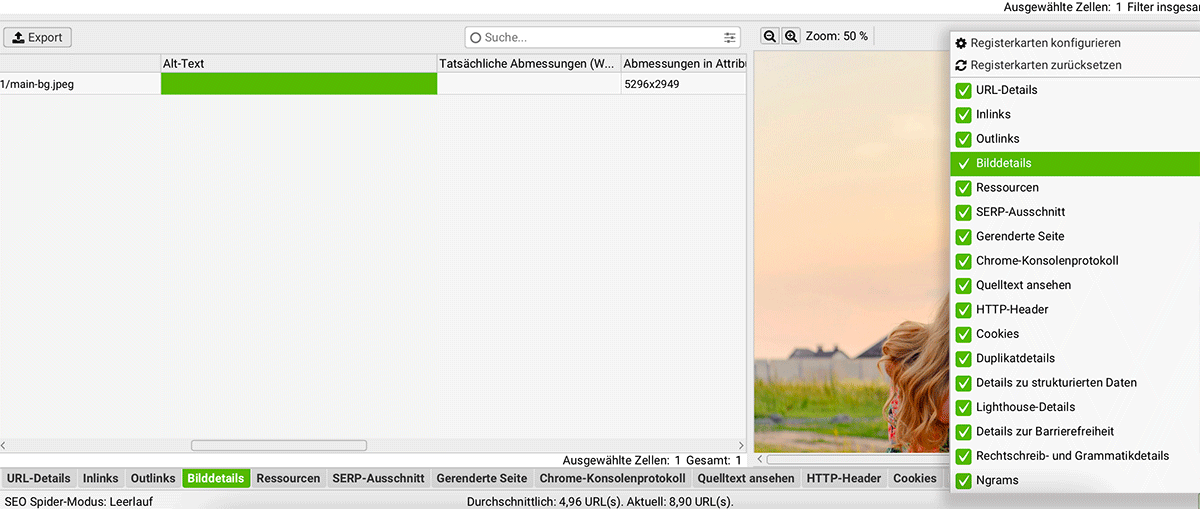
- URL-Details: Zeigt Informationen zur aktuellen Seite, z. B. Titel, Beschreibung und Statuscode.
- Inlinks: Zeigt, von welchen anderen Seiten deiner Website auf diese Seite verlinkt wird.
- Outlinks: Zeigt, wohin diese Seite verlinkt – also alle Links von dieser Seite zu anderen Seiten.
- Bilddetails: Zeigt Informationen über alle Bilder auf der Seite, z. B. Alt-Texte und Dateigrößen.
- Ressourcen: Listet alle Dateien auf, die zum Anzeigen der Seite geladen werden, z. B. Bilder, Skripte, CSS.
- SERP-Ausschnitt: Zeigt eine Vorschau, wie die Seite bei Google in den Suchergebnissen aussehen würde.
- Gerenderte Seite: Zeigt die Seite so, wie sie ein Browser nach dem Laden sieht – inklusive dynamischer Inhalte.
- Chrome-Konsolenprotokoll: Zeigt Fehlermeldungen oder Warnungen beim Laden der Seite (wie in der Browser-Konsole).
- Quelltext ansehen: Zeigt den HTML-Code der Seite, wie er an den Browser gesendet wird.
- HTTP-Header: Zeigt technische Informationen, die beim Aufruf der Seite mitgesendet werden.
- Cookies: Zeigt alle Cookies, die von der Seite gesetzt werden – wichtig für Datenschutz.
- Duplikatdetails: Zeigt, ob es Seiten mit gleichem oder sehr ähnlichem Inhalt gibt.
- Details zu strukturierten Daten: Zeigt, ob spezielle Daten für Suchmaschinen vorhanden sind, z. B. Bewertungen oder Events.
- Lighthouse-Details: Ergebnisse eines Website-Tests zu Ladegeschwindigkeit, SEO, Barrierefreiheit und Technik.
- Details zur Barrierefreiheit: Prüft, ob die Seite auch für Menschen mit Einschränkungen gut nutzbar ist.
- Rechtschreib- und Grammatikdetails: Zeigt mögliche Fehler im Text der Seite.
- Ngrams: Zeigt häufig verwendete Wortkombinationen auf der Seite.
Visualisierungen von Screaming Frog
Hier kannst du entscheiden, ob die Visualisierungen deiner Präsentation oder deinen Daten überhaupt einen Mehrwert geben. Bei den Diagrammen habe ich diesen Blog genommen, um bei einer größeren Datenmenge die Technik sichtbarer zu machen.
Wenn du auf ein Element deiner Visualisierung mit der Maus drüberfährst, bekommst detailliertere Informationen.




Ergebnisse sammeln und strukturieren
In der Kaufversion kannst du Tabellen speichern und die Ergebnisse zeitlich miteinander vergleichen. Ich nutze dazu Google-Drive-Tabellen, um alles an einem Ort zu haben, was Suchmaschinenoptimierung betrifft. Dazu exportiere ich zuerst die Daten und danach importiere ich diese in Google Drive.

Die erzeugte .csv-Datei kannst du z.B. über Google Drive importieren und deine gesammelten Daten organisieren. Alternativ dazu kannst du die Tabelle auch gleich in Google Drive öffnen und weiterbearbeiten.
7 Gründe, warum die Registerkarten der Fußzeile nicht funktionieren
Viele Funktionen in Screaming Frog zeigen nur dann Daten an, wenn bestimmte Voraussetzungen erfüllt sind. Alles leider nur in der in der Pro-Lizenz möglich.
1. Falscher Modus eingestellt
- Standardmäßig wird nur der HTML-Code geladen.
- Viele Inhalte (z. B. Texte, Bilder oder Links) werden aber erst durch JavaScript angezeigt.
- Lösung: Unter „Konfiguration > Spider > Rendering“ JavaScript aktivieren.
Rendern bedeutet ganz einfach, das der Quellcode vom Browser interpretiert wird und uns bildhaft angezeigt wird.

2. Die Website blockiert den Crawler
- Manche Seiten lassen keine automatischen Programme wie Screaming Frog zu.
- Mögliche Hinweise: Fehlercode 403, nur Startseite wird geladen, oder keine Inhalte sichtbar.
- Lösung: Login einrichten unter „Konfiguration > Authentifizierung“ oder die robots.txt der Seite prüfen.
Das heisst: Du richtest den Login direkt in Screaming Frog ein, damit der Crawler sich automatisch auf der Website einloggen kann, bevor er mit dem Crawlen beginnt. Also: Du loggst dich nicht manuell im Browser in deiner Website ein, sondern gibst deine Login-Daten im Programm ein, wenn diese einen geschützten Bereich hat.
3. Funktionen sind nicht aktiviert
- Viele Tabs (z. B. Lighthouse, strukturierte Daten, Rechtschreibung) müssen erst eingeschaltet werden.
- Lösung: In „Konfiguration > Spider“ oder „Konfiguration > API“ die gewünschten Funktionen aktivieren.
API ist eine Schnittstelle zu einem anderen Programm, darüber können diese Programme Daten austauschen.
4. Kostenlose Version ist eingeschränkt
- Es können nur 500 URLs gecrawlt werden.
- Einige Funktionen wie JavaScript-Rendering, API-Verbindungen oder Export sind nicht verfügbar.
- Lösung: Lizenz kaufen, wenn du mehr brauchst.
5. Inhalte werden dynamisch per JavaScript geladen
- Wenn Inhalte erst nach einem Klick oder beim Scrollen erscheinen, sieht Screaming Frog sie im Standardmodus nicht.
- Lösung: JavaScript-Rendering aktivieren, damit die Seite wie im echten Browser geladen wird.
Durch JavaScript erhältst du bestimmte Effekte, z.B. ein Bild zoomt beim Öffnen der Seite herein.
6. Falsche Crawl-Einstellungen
- Bestimmte Dinge wie Bilder, PDFs oder externe Links können in den Einstellungen deaktiviert sein.
- Lösung: In „Konfiguration > Spider“ prüfen, ob alles angehakt ist, was du analysieren willst.
Screaming Frog downloaden
Die Homepage bietet dir die richtige Software für dein Betriebssystem an, also Windows oder Mac.
4 Kommentare zu „Screaming Frog – SEO Analyse – Tutorial“